Search Indexation🔗
Overview🔗
A key feature of the Textkernel Connector is the search indexation engine. This infrastructure copies relevant Salesforce Candidate and Vacancy record data into the Textkernel Search index. This activity is also known as indexation of the records. Once the data is in Textkernel's index it can be accessed using Textkernel's semantic search and match features. The integration provides several features:
- flexible mapping of the Salesforce object fields to the Textkernel index data model;
- importing all candidate and vacancy records, or a subset of them;
- monitoring the indexation status of these records;
- automatically retry the indexation if an error occurred;
- skip indexation requests when neither mapped data fields nor the binary CV/resume have changed since the last successful indexation event.
There are 2 indexation engines available in the integration: 1. The standard push indexation architecture, which pushes changes from Salesforce into Textkernel 2. The optional high-throughput indexation addon is a pull architecture, which pulls data from Salesforce into Textkernel
Textkernel Indexing Status tracking🔗
For each Candidate or Vacancy record that must be indexed in Textkernel Search, the integration creates a related-object record Textkernel Indexing Status (the TIS record). The TIS keeps track of the indexation status, whether the record in Textkernel is awaiting an update, whether the record was indexed successfully in Textkernel Search, when it was last indexed, and if the record was not successfully indexed it captures a detailed error message.
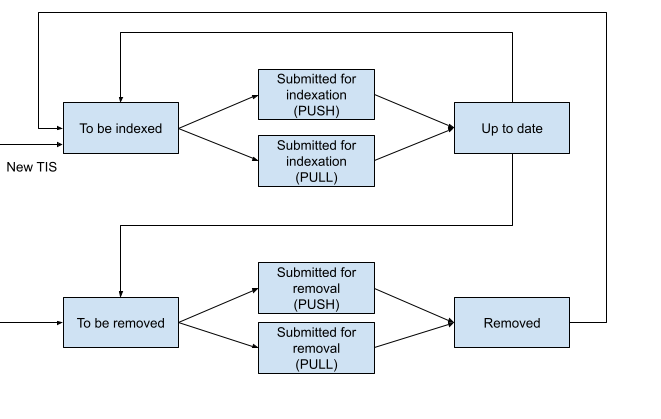
Starting with release 5.6.4, the indexation status of a record can be one of the following:
- Up to date: indicates that record has been properly indexed in Textkernel Search and the data is up to date;
- To be indexed: for every new candidate/vacancy record created in Salesforce or existing record that has been updated (and that meets the indexation filter - see below), the status of the related Textkernel Indexing Status record is set to To be indexed. Records with this status are queued and indexed again in Textkernel Search;
- Submitted for indexation (Push): the mechanism that pushes indexation requests from Salesforce to Textkernel is working on the record and it is being actively indexed
- Submitted for indexation (Pull): the HTI pull indexation feature is working on the record and it is being actively indexed
- To be removed: records marked with this status are queued to be removed from Textkernel Search;
- Submitted for removal (Push): the mechanism that pushes removal requests from Salesforce to Textkernel is working on the record and it is being actively removed from the index
- Submitted for removal (Pull): wthe HTI pull indexation feature is working on the record and it is being actively removed from the index
- Removed: candidate/vacancy records whose related Textkernel Indexing Status is set to Removed have been deleted from the Textkernel Search index.
At a regular interval, the integration runs and updates all candidate/vacancy records that are marked with the status To be indexed. These records are queued and updated in Textkernel Search, then the status of the records are set to Up to date if the indexation completed successfully.
This background job makes sure that Candidate and Vacancy records in Textkernel Search are always indexed (or removed) within a few minutes from their change in Salesforce, ensuring that users have always access to the most updated data.
This diagram shows how the Indexing Status values change:
Textkernel Indexing Status record fields🔗
The Textkernel Indexing Status record (TIS) is used to keep track of the execution of the indexation job. There is no need for users or admins to modify these values directly. The integration will automatically manage them. The TIS uses the following fields:
- Candidate: lookup field that contains a reference to the related Candidate record (in the case the Textkernel Indexing Status record refers to a candidate);
- Vacancy: lookup field that contains a reference to the related Vacancy record (in the case the Textkernel Indexing Status record refers to a vacancy);
- Status: the indexation status of the candidate/vacancy record. See listing of possible status values in documentation above.
- Last indexing request: timestamp of the last attempt to index the related candidate/vacancy record;
- Last successful indexing: timestamp of the last successful indexation of the candidate/vacancy record;
- Priority: it indicates the indexation priority of this candidate/vacancy record (see below the paragraph Priority);
- Response code and message: in case of errors, these fields contain useful information that can help the Textkernel Support team to identify what the issue is; for candidate/vacancy records successfully indexed, the response code field is set to 200;
- Error severity code: in case an error occurred while indexing, this field describes the severity of the error where 1 means a temporary error, 2 a configuration error and 3 a permanent error (see below from more information about the errors and the indexing retry mechanism);
- Next retry: if an error occurred while indexing the related record, this field shows the timestamp of the next indexing retry;
- Retry number: if an error occurred while indexing the related record, this field contains the number of times the connector has tried to index the record.
- Full update: deprecated since version 6.10.0
- Is Locked: (Boolean) deprecated since version 5.6.4
- Last indexing request checksum: concatenation of the unique Salefsorce binary CV/resume object ID and checksum of the last successful indexation request XML sent to TK index; used to check to see whether mapped data has changed since the last request
- Last skipped indexing request: timestamp of the last skipped indexing request (ie, because the checksum of the requested update was the same as the last indexing status request).
- Is Candidate: (Boolean) set to True if this TK indexing status record is/was linked to a Candidate rather than a Vacancy. Set to False if this record is linked to a Vacancy.
- Indexation Request Submission Time: set to current date-time when integration selects a record to be indexed OR removed.
- Next indexing request checksum: will be used in future release
- Index request when busy - indicates that there was a request to update a record to the Textkernel Index when the record was actively being updated or removed. When this happens, the current date-time is stored in this field. When the current indexation update operation completes, the integration checks this field. If there is a pending request it sets the status to "To Be Indexed" instead of "Up to date" or "Removed"
- Removal request when busy - indicates that there was a request to remove a record from the Textkernel Index when the record was actively being updated or removed. When this happens, the current date-time is stored in this field. When the current indexation update operation completes, the integration checks this field. If there is a pending request it sets the status to "To Be Removed" instead of "Up to date"
Excluding records from indexation🔗
The integration can be configured to filter out Candidate or Vacancy records that should not be indexed in Textkernel Search, for instance, expired or inactive vacancies. Filtering is configured in the data mapping admin user interface in the Textkernel managed package.
Automatic error handling and retry mechanism🔗
Temporary or permanent errors can occur when indexing Candidate and Vacancy records in Textkernel Search. When this happens, additional information about the error can be found in the related Textkernel Indexing Status record.
Textkernel classifies the errors based on their severity:
- Severity level 1, temporary error: the error is caused by a temporary outage or degradation of the service. The connector will attempt to index the record again on the next retry. After 10 attempts, the record is put in an error state.
- Severity level 2, recoverable error: this error is caused by a misconfiguration (e.g. wrong credentials) and it requires human intervention to be fixed. Please report this to the administrator of the integration in your organization.
- Severity level 3, permanent error: this error occurs when the Candidate/Vacancy record cannot be indexed in Textkernel Search, for instance because of an unsupported file type of the candidate resume. Retrying will not solve the issue.
When an error of severity level 1 occurs, the connector will automatically attempt to index the record again, for 10 times every 60 minutes. The number of attempts and the time of the next retry are visible in the fields Retry Number and Next Retry of the Textkernel Indexing Status.
Manually forcing indexation🔗
Info
This feature is only available once the admin has configured it.
If you want to force a Candidate or Vacancy record to be immediately indexed or deleted from Textkernel Search, the related Textkernel Indexing Status record offers two actions Update in index and Delete from index, which trigger an immediate update/deletion of the record.
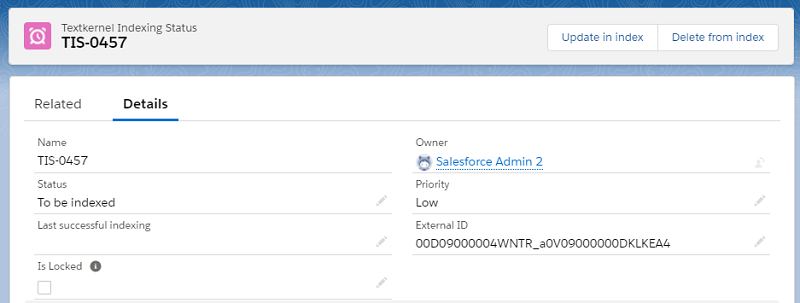
This can be useful if an error occurred and you want to retry immediately to test if it is resolved.
Monitoring indexation🔗
This section requires users to have access to the related object Textkernel Indexing Status.
One of the most common reasons why a Candidate or Vacancy record is not visible or not updated in Textkernel Search is an indexation error. You can check if an error occurred looking at the related Textkernel Indexing Status record.
If the field Status is set to Up to date, the Candidate or Vacancy record has been successfully indexed to Textkernel Search and the cause must be searched somewhere else.
If the field Status is set to To be indexed, we need to investigate further:
- if the record was recently created/updated/deleted and the field Last indexing request is empty, the record has been queued by the connector but still not sent to Textkernel Search. The connector will pick it up and index it in one of the next runs. If you want to force the record to be indexed immediately, you can use the action Update in index (if available in your Salesforce configuration);
- if the field Last indexing request has a timestamp anterior to the record creation/update/deletion, the record has been queued for indexing but not picked up yet. The connector will index it in one of the next runs. Fields like Response Code, Response Message, Error Severity Code, Retry Number and Next Retry refer to the previous indexation request (if the Candidate or Vacancy record is not newly created);
- if the field Last indexing request has a timestamp subsequent to the record creation/update/deletion, an error occurred and the fields Response Code, Response Message, Error Severity Code, Retry Number and Next Retry contain information about the error and when then next indexation retry will happen.
If the Status is set to To be removed, the same logic described above for the field Last indexing request applies.
If the Status is set to Removed, the Candidate or Vacancy record has been successfully deleted from Textkernel Search. Even though the record is not indexed anymore in Textkernel Search, the related Textkernel Indexing Status record is kept for historical tracking purposes.
Tip
Administrators can monitor the status of the indexation from the Monitoring page in the Textkernel App.
This helps to investigate the cause a record is deleted from Textkernel Search in case it should have not.
Exporting records for support investigation🔗
When investigating a problem with indexation, sometimes the problems are data-dependent. To analyze these scenarios, the Textkernel Support team may ask to see the Salesforce record data that triggered a problem.
You can easily export the record data by visiting the related Textkernel Indexing Status record and clicking on the Get TK Record XML and/or Get TK CV/Vacancy File buttons.
- Get TK Record XML: generates the XML file that contains the record information stored in Salesforce;
- Get TK CV/Vacancy File: downloads the binary file attached to the Salesforce record (the candidate resume or a file containing the job description - if any - that is sent to the Textkernel Search! index).
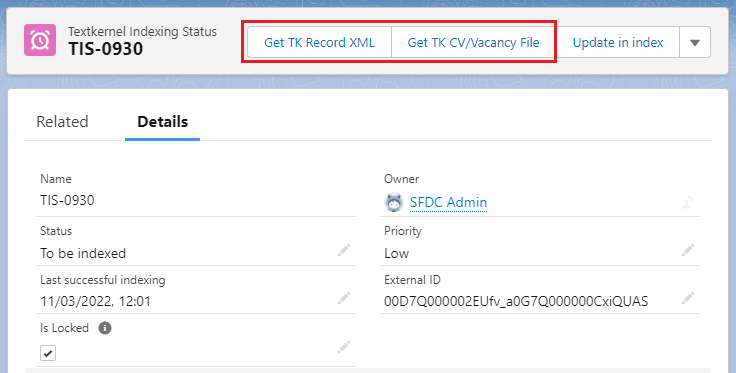
When requested by the Textkernel Support team, please provide both files
Note
The Get TK Record XML and Get TK CV/Vacancy File buttons might need to be added to the page layout if they are not visible in the Textkernel Indexing Status record page.
Re-synchronization of Candidates/Vacancies from Salesforce to the Textkernel Index🔗
In unusual cases you may want to re-synchronize your Salesforce data to the Textkernel Index. For example, if you add a new field in your search data-mapping, unless you re-synchronize, the data from that new field will be missing from the records that are already in the index.
Below are the procedures to re-index/re-delete records from the Textkernel index. For simple scenarios, the integration package has a feature to reindex a chunk of 10,000 records at a time. For more complex re-indexation scenarios (eg very large indexes), we also document the procedure for an admin to manually query and reset the indexation status records.
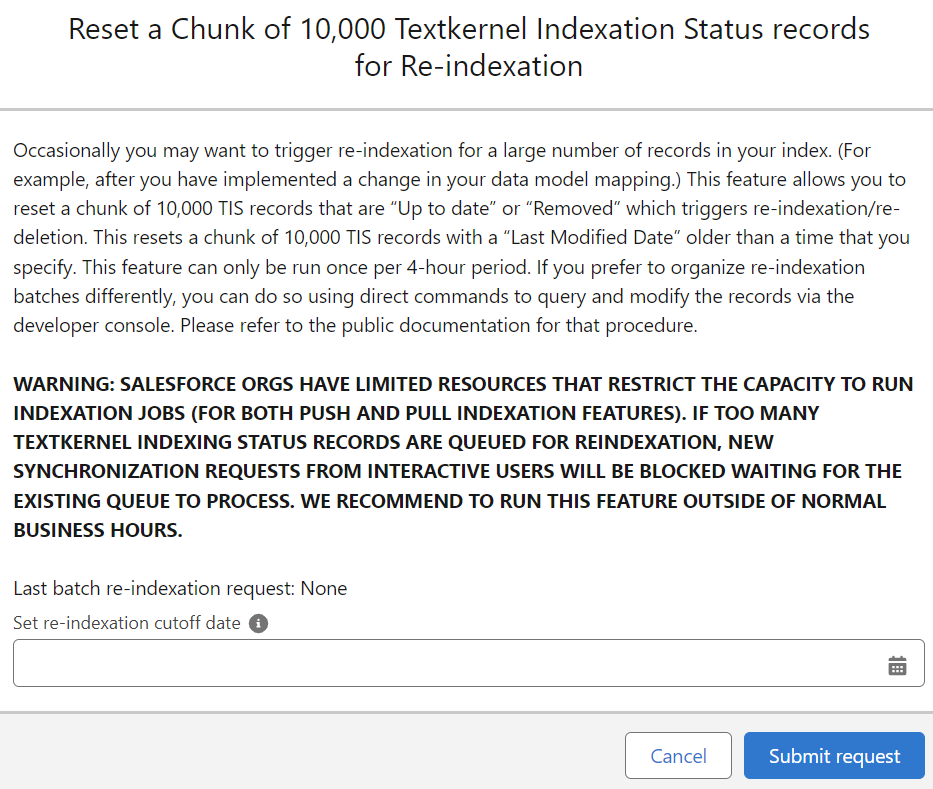
Basic procedure: re-synchronizing a chunk of 10,000 records🔗
This feature allows SF admin to reset a chunk of maximum 10,000 TIS records that are “Up to date” or “Removed” with a push of a button. The records being reset are selected based on the “Last Modified Date” of the TIS record being older than a cutoff time specified by the Salesforce admin user.
Important
This feature can only be run once per 4-hour period. This is to prevent situations where the synchronization queue is overwhelmed with re-synchronization work..
Follow the steps below to re-synchronize using the button:
-
Go to the Textkernel App
-
Go to the Monitoring tab. Under the Indexation Status section on the left, you’ll see the Reindex Chunk button
-
Click the Reindex Chunk button
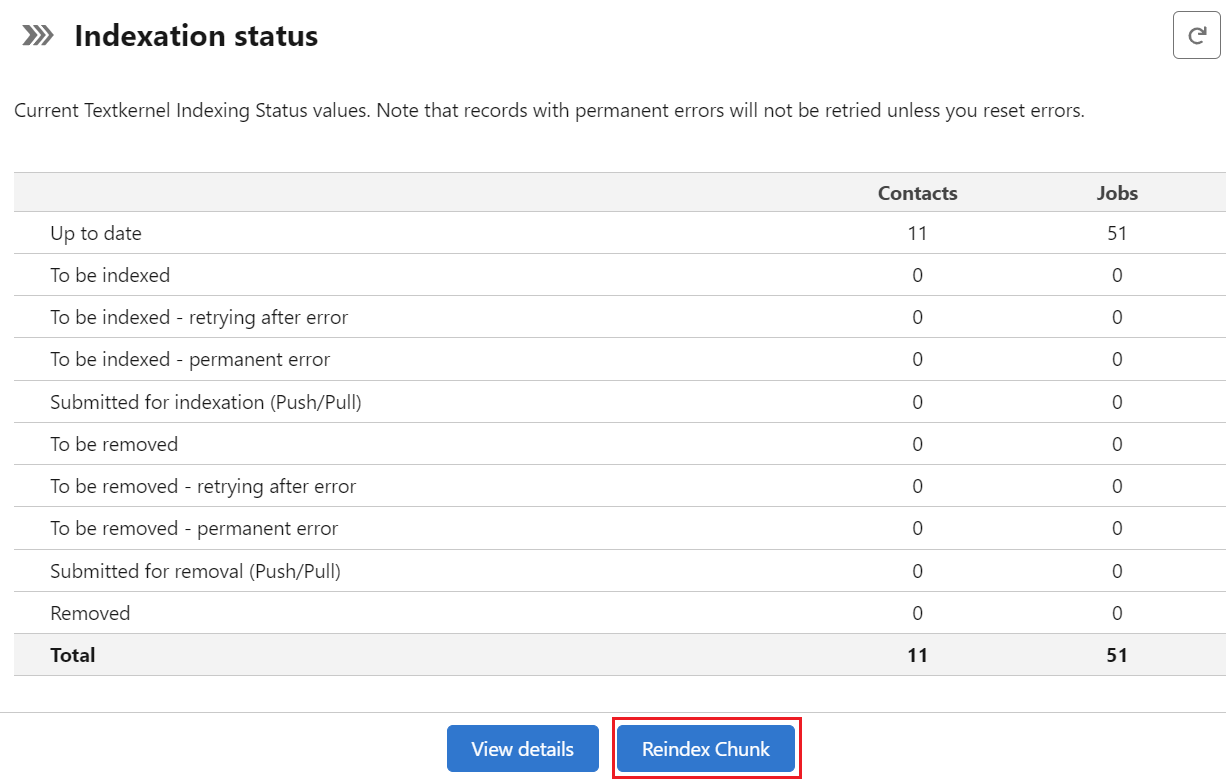
- On the modal window, select the re-indexation cut-off date
- Click on the Submit Request button.
Advanced procedure: re-synchronizing records based on a query🔗
This section describes how to manually re-index/re-delete sets of Candidate/Vacancy records to the Textkernel index. We first identify a batch of Textkernel Indexing Status (TIS) records that should be reset, and then we clear the indexation status data stored on the TIS records.
Each procedure has 3 steps:
-
Run a SOQL query to identify the target record IDs
-
Split your ID list into batches
-
Change the status on those records to re-sync with the Textkernel Index
Warning
IF YOU RESET A LARGE NUMBER OF TEXTKERNEL INDEXING STATUS (TIS) RECORDS IT WILL BREAK THE INDEXATION PROCESS BY COMPLETELY CONSUMING YOUR INDEXATION QUEUE WITH REQUESTS FOR REINDEXATION. This would block other update requests made by your system. You should reset the records in smaller batches that allow normal indexation and removal to continue. The indexation throughput is roughly 3000 records per hour.
IT IS STRONGLY RECOMMENDED THAT YOU RUN RE-INDEXATION BATCHES OUTSIDE OF NORMAL BUSINESS HOURS.
If you accidentally reset too many TIS records, you can revert the status back to the previous status to free up indexation capacity.
For the 3rd step, you can use Salesforce data loader to load your work batches.
Use Salesforce Data Loader🔗
Data loader is a standard Salesforce tool for making bulk record changes. Refer to Salesforce documentation on Data Loader.
(Note that you need to set data loader properly to overwrite null values).
The overall process for Data Loader, is that you:
-
build a .csv file per batch with the TIS IDs from the query and the desired data field changes for the records
-
then you bulk upload the .csv files using data loader to run an UPDATE operation.
-
Repeat this and upload additional batches, while spacing out the batches over time so that you don’t overwhelm the indexation queue.
Procedure to resynchronize a batch of records🔗
Run this query to return list of IDs to re-sychronize indexed records (batch of 10k records that were last modified before the specific date-time, 2024-06-05T00:00:00+00:00) :
SELECT Id FROM Textkernel1__IndexingStatus__c
WHERE Textkernel1__Status__c = 'Up to date'
AND LastModifiedDate <= 2024-06-05T00:00:00+00:00
LIMIT 10000
Given the ID list returned from the query above, build a .csv file for Data Loader.
For the TIS record IDs in the batch, to re-index them, update them with the values below:
TEXTKERNEL1__ERRORSEVERITYCODE__C = <blank>
TEXTKERNEL1__FULLUPDATE__C = true
TEXTKERNEL1__INDEXATIONREQUESTSUBMISSIONTIME__C = <blank>
TEXTKERNEL1__INDEXINGDATE__C = <blank>
TEXTKERNEL1__INDEXREQUESTWHENBUSY__C = <blank>
TEXTKERNEL1__ISLOCKED__C = false
TEXTKERNEL1__LASTINDEXINGCHECKSUM__C = <blank>
TEXTKERNEL1__LASTSKIPPEDINDEXATION__C = <blank>
TEXTKERNEL1__LASTSUCCESSFUL__C = <blank>
TEXTKERNEL1__NEXTRETRY__C = <blank>
TEXTKERNEL1__PRIORITY__C = Low
TEXTKERNEL1__REMOVALREQUESTWHENBUSY__C = <blank>
TEXTKERNEL1__RESPONSECODE__C = <blank>
TEXTKERNEL1__RESPONSEMESSAGE__C = <blank>
TEXTKERNEL1__RETRYNUMBER__C = <blank>
TEXTKERNEL1__STATUS__C = To be indexed
Procedure to re-delete a batch of records🔗
Return list of IDs to re-delete (batch of 10k records that were last modified before the specific date-time, 2024-06-05T00:00:00+00:00) :
SELECT Id FROM Textkernel1__IndexingStatus__c
WHERE Textkernel1__Status__c = 'Removed'
AND LastModifiedDate <= 2024-06-05T00:00:00+00:00
LIMIT 10000
Given the ID list returned from the query above, build a .csv file for Data Loader.
For the TIS record IDs in the batch, to re-delete them, update them with the values below:
TEXTKERNEL1__ERRORSEVERITYCODE__C = <blank>
TEXTKERNEL1__FULLUPDATE__C = true
TEXTKERNEL1__INDEXATIONREQUESTSUBMISSIONTIME__C = <blank>
TEXTKERNEL1__INDEXINGDATE__C = <blank>
TEXTKERNEL1__INDEXREQUESTWHENBUSY__C = <blank>
TEXTKERNEL1__ISLOCKED__C = false
TEXTKERNEL1__LASTINDEXINGCHECKSUM__C = <blank>
TEXTKERNEL1__LASTSKIPPEDINDEXATION__C = <blank>
TEXTKERNEL1__LASTSUCCESSFUL__C = <blank>
TEXTKERNEL1__NEXTRETRY__C = <blank>
TEXTKERNEL1__PRIORITY__C = Low
TEXTKERNEL1__REMOVALREQUESTWHENBUSY__C = <blank>
TEXTKERNEL1__RESPONSECODE__C = <blank>
TEXTKERNEL1__RESPONSEMESSAGE__C = <blank>
TEXTKERNEL1__RETRYNUMBER__C = <blank>
TEXTKERNEL1__STATUS__C = To be removed