Modelling Skills data in your Salesforce-based ATS🔗
In this section we discuss modelling Skills data in your Salesforce-based ATS and best practices to leverage Textkernel's skills knowledge when parsing candidates and importing Market IQ records.
Skills use cases🔗
In the end, the approach to skills modelling in Salesforce is driven by the use cases where you want to use skills.
Indexation to enable search and match🔗
If you are using Textkernel search and match to organize your Candidates and Vacancy data, then skills will be extracted as part of enriching the profiles when building the Textkernel search index. If this is your primary use case, then you can benefit from Textkernel skills quite easily.
If you also maintain skills data in your ATS, that can also be added during indexation. However, bear in mind that manually updating skills on your candidates and jobs can be quite a lot of effort for the recruiting team. Automatic extraction can be very helpful.
Skills reporting inside Salesforce🔗
If you want to do reporting on skills inside your Salesforce ATS (for example on candidates or jobs) then you want to consider what skills data model works best for you. For reporting, it is helpful to use a standardized naming convention for the skills. For example a skill like "MS Excel" has a variety of spellings and variants: "Microsoft Excel", "Excel", "MSFT Excel", etc, and the term needs to be normalized to a standard term to make it easier to compare the reports. Fortunately, Textkernel offers normalized skill extraction both during Candidate CV parsing flows, and when importing leads from Market IQ.
Important
Skills can consume a significant amount of structured data storage in Salesforce. If you have 500,000 Candidate records, and you expect roughly 20 Skills per Candidate, then you can easily end up with 10 million Skills records.
Skills data model inside the managed package🔗
Textkernel extracts skills during recruiter CV parsing and when importing candidates from external candidates. The skills are linked to the Textkernel Imported Candidate record, which is created to land the parsed data inside Salesforce and provide recruiters with a place to review data before completing the import.
With managed package version 6.x, Textkernel introduced a new skill data model (version 2). Skill data model version 1 is still available, but it is now deprecated. You can switch between which model you want to use via the custom settings. (See the procedure later in this document).
Skills Model Version 1 (package version 6.x and earlier)🔗
Skills were simply imported as Textkernel Imported Skill detail records of the master-detail relationship to the TIC record. If skill normalization was enabled, then normalized values were added alongside extracted values on the skill record.
Skill extraction on imported Textkernel Market IQ Jobs (leads) was not supported.
This model is illustrated in the diagram:

In many cases, the ATS wants to maintain a customizable skill model outside of Textkernel's ontology. Because of this, a separate skill model would be setup outside of Textkernel's package. In an ATS where the Contact object represents the candidate and where Job is the object representing a job, then the skill model in the ATS replicates the model inside the package. This also keeps the ATS data model independent of changes to the Textkernel data model inside the package.
The ATS model is illustrated in the diagram:

To copy the skill information from the internal package skill model over to the ATS skill model, a Flow or APEX code can be setup to copy over the skills. It is also important to periodically clean out old TIC records and their Skill details to manage data storage.
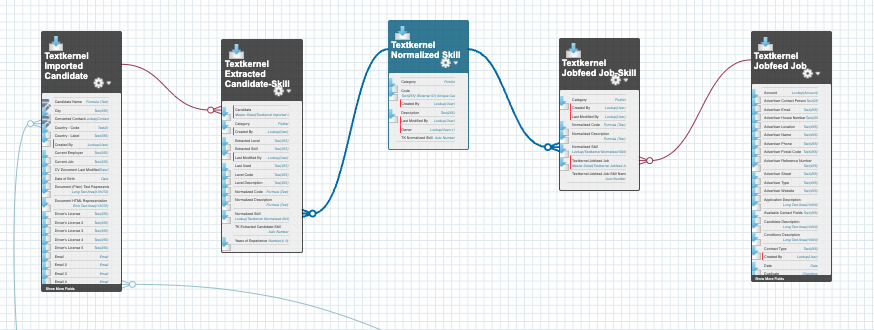
Skills Model Version 2 (package version 6.x and later)🔗
Skills are now imported as Textkernel Extracted Candidate-Skills, which are detail records of a master-detail relationship to the TIC record. If skill normalization is enabled, then these new records act as a join/bridge table to a Textkernal Normalized Skill record, which contains the normalized, representative skill concept.
In addition, skills can be extracted and imported from Market IQ leads during import, and they are created as Textkernel Market IQ Job-Skill records. The model is similar to that of Candidate parsing, except there is no concept of a raw/extracted skill with Market IQ. Only normalized skills are available. The Market IQ Job-Skills are again the detail of a master-detail relationship, but with the Textkernel Market IQ Job. The records link the Market IQ Job to the Textkernel Normalized Skill records.
This model is illustrated in the diagram:
Again, a separate, customizable, but similar skill model can be setup outside of Textkernel's package. In an ATS where the Contact object represents the candidate and where Job is the object representing a job, then the skill model in the ATS replicates the model inside the package.
The ATS model is illustrated in the diagram:
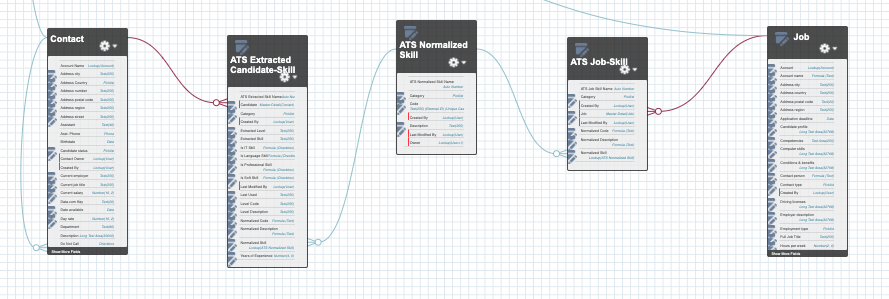
To copy the skill information from the internal package skill model over to the ATS skill model, a Flow or APEX code would be setup to copy the skills from newly-parsed Candidates and/or new Jobs creates from Textkernel Market IQ Jobs. It is recommended to check and de-duplicate the normalized skill records so that each normalized concept only has one record. As with the v1 skill model, you should periodically clean out old, unneeded records, to manage storage space.
There are other ways to organize the skill information, but this approach maintains the most flexibility, particularly if reporting is the target use case.
Activating skills model v1 (package version 6.x and later)🔗
It is advised for all new implementations to use Skill data model version 2.
However, existing customers may have automation linked to the deprecated Skill data model version 1. So, we provide continuity by allowing customers to enable the old skill data model if desired. The setting for this is in the Custom Code Settings area in Salesforce Setup. Normally customers don't need to make changes in this area, however, this is a case where it might be necessary.
Here is the procedure:
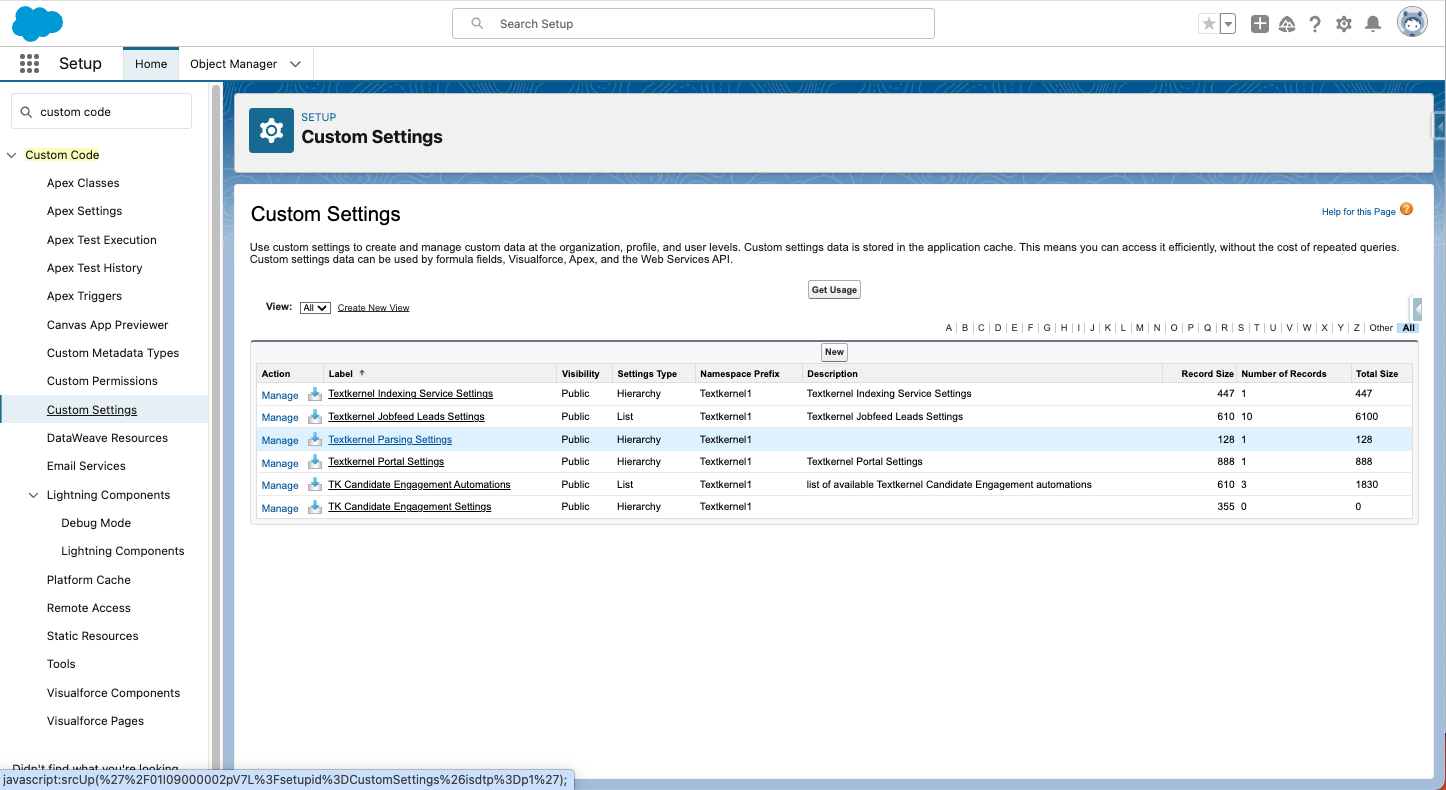
- Navigate to Salesforce Sestup -> Custom Code -> Custom Settings
-
Click Manage next to Textkernel Parsing Settings.
-
Click the edit button so that you can update the settings.
-
On the screen, put a tick in the checkbox Use v1 Skill Data Model (Deprecated).
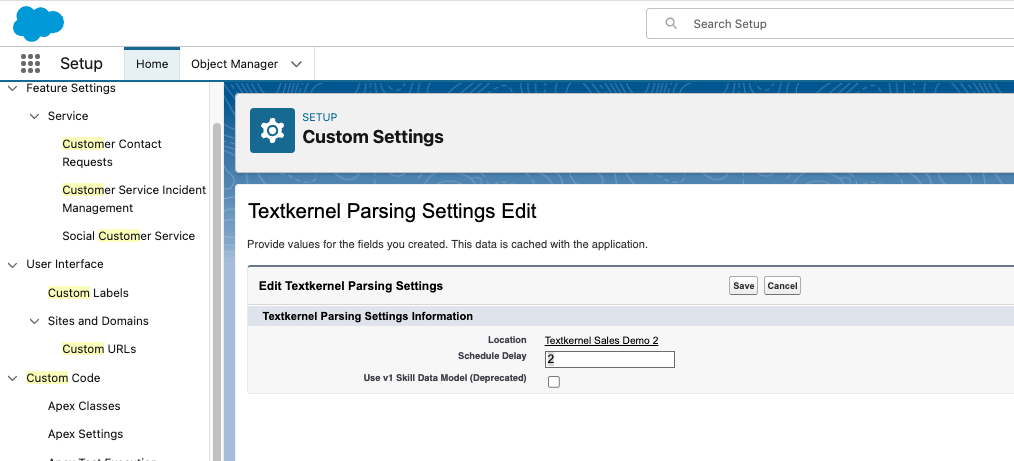
- Save your change
If you have set this, during Candidate parsing the v1 Skill data model will be used.