Getting Started
CV/Resume Parser Overview🔗︎
The Textkernel Resume/CV Parser takes in documents and returns structured json responses representing a human understanding of the data. Your integration task isn't to just get the API call to succeed, but rather to understand the bigger picture and how to properly configure each transaction. For example, different configurations are needed for processing batches of resumes, resumes from college students, or even resumes coming from Australia or New Zealand. Below we will discuss the most important points to understand for your integration.
To parse a resume accurately, you must tell us when that resume was written or submitted to your system. This is not obvious, but it is 100x more important than any other setting when parsing resumes. We cannot determine that date from the resume. You must specify it explicitly. We refer to this date as the Document Last Modified Date.
Document Last Modified Date (formerly Revision Date)🔗︎
Document Last Modified Dates are required for every transaction because they make or break the accuracy of parsing. Document Last Modified Dates tell the parser when the document was last revised, which impacts the interpretation of terms such as 'current'. In a candidate upload scenario, it's safe to assume a candidate is uploading a version of their resume that's reasonably current and that you can use today's date as the Document Last Modified Date. In any other situation, that means the resume was received sometime before today.
If you leave this date off and parse a batch of 1 million resumes, your oldest and least employable candidates will be distorted as the most experienced, most employable, ready-to-go-to-work candidates despite having received the resume years ago.
How do I determine the correct Document Last Modified Date?🔗︎
The most correct Document Last Modified Date is the last time the file was authored. Since resumes can come from many different places, there are a few things to look for when determining the most correct Document Last Modified Date. Here are a few use cases and our recommended approach for determining the correct date.
File upload control🔗︎
When a user uploads a file directly from their file system, we would recommend using the last modified date of the file. More documentation of File.lastModified can be found at https://developer.mozilla.org/en-US/docs/Web/API/File/lastModified.
Batch of resumes on disk🔗︎
When you have a batch of resumes on disk that you are processing you need to look at the last modified date of the files and make sure that they all aren't the same, or within seconds of each other. If those dates are the same, then the metadata of the file was overwritten at some point during file transfer and isn't valid. You need to go back to the source and move those files over using a different approach.
Batch of resumes from a database🔗︎
When you have a batch of resumes from a database those are usually stored with a profile. If the date modified for the file was stored in the database you should use that, but if not you should look for a last modified date on the profile and use that.
Sourcing resumes from a third-party such as a job board🔗︎
When receiving resumes from a third-party API they should provide this date in the API response. If you don't see a date, reach out to the third-party to clarify.
Do Not Repeatedly Retry Failed Parsing Transactions🔗︎
You must institute processing safeguards and kill switches to ensure that you do not violate the AUP and probably use all your account credits – and more – in a "futile loop of Einsteinian doom". An example of a "futile loop of Einsteinian doom" is logic such as this:
Never ever implement this type of logic🔗︎
HttpStatusCode responseCode;
foreach (Document doc in batchOfDocuments) {
do {
responseCode = SendDocumentToServiceForProcessing(doc);
} while (responseCode != HttpStatusCode.Ok)
}
The problem with the above loop is that when a particular document fails, it will be resubmitted for processing an infinite number of times, but with no chance that the 765,498th time, or any other time, it will magically succeed.
Batch Parsing Concurrency🔗︎
When your application needs to parse a set or batch or folder of selected resumes, you MUST parse them one at a time and never concurrently. Parsing one at a time allows you to process over 100,000 documents per day (30 million per year). NEVER EVER program concurrent parsing into software that you provide to end users.
The vast majority of programming errors that cause concurrency violations are due to one of these two integration errors:
- You allow recruiters to select resumes from a directory and then you parse those in a batch that sends parallel concurrent transactions rather than processing them serially one by one. There is no need to process such batches in a parallel state, as humans cannot read XX resumes per second. You MUST parse such resumes in a For-Each style of loop, one at a time, and never concurrently**.
- You have a timed process that kicks off a batch at the same time(s) every day, and this batch is processing transaction unnecessarily in parallel rather than serially one at a time. Again, there is no need to process XXX transactions per second rather than staying within the concurrency limit.
When you have a demonstrable, pressing business need to parse a huge amount of documents in a short period of time (defined as more than 100,000 documents in less than 12 hours for a valid reason that they must be parsed in that small time frame), you must ensure that you never exceed your maximum allowed concurrent requests. This value is returned in every response in the Info.CustomerDetails.MaximumConcurrentRequests field. You must refer to this value before you start a parsing batch, and after every 1,000 transactions and set your concurrent requests accordingly to not violate our AUP. The value of MaximumConcurrentRequests may change up or down dynamically, so never assume it has not changed.
All modern cloud systems implement and enforce such concurrency limits. See, for example, this discussion by Google. If you have any questions about batch transactions, please reach out to TXsupport@bullhorn.com. We prefer helping you integrate correctly the first time rather than helping you fix it later!
How Does Resume Parsing Work?🔗︎
What we call parsing is actually a multi-step process. First, we convert the source document to plain text, analyze it, and decide if the text is usable for parsing. If the plain text is not usable, we immediately return a response indicating the issue. If the plain text is usable it continues on to the parser and then returns a parsed document in the response. The graphic below illustrates this workflow.
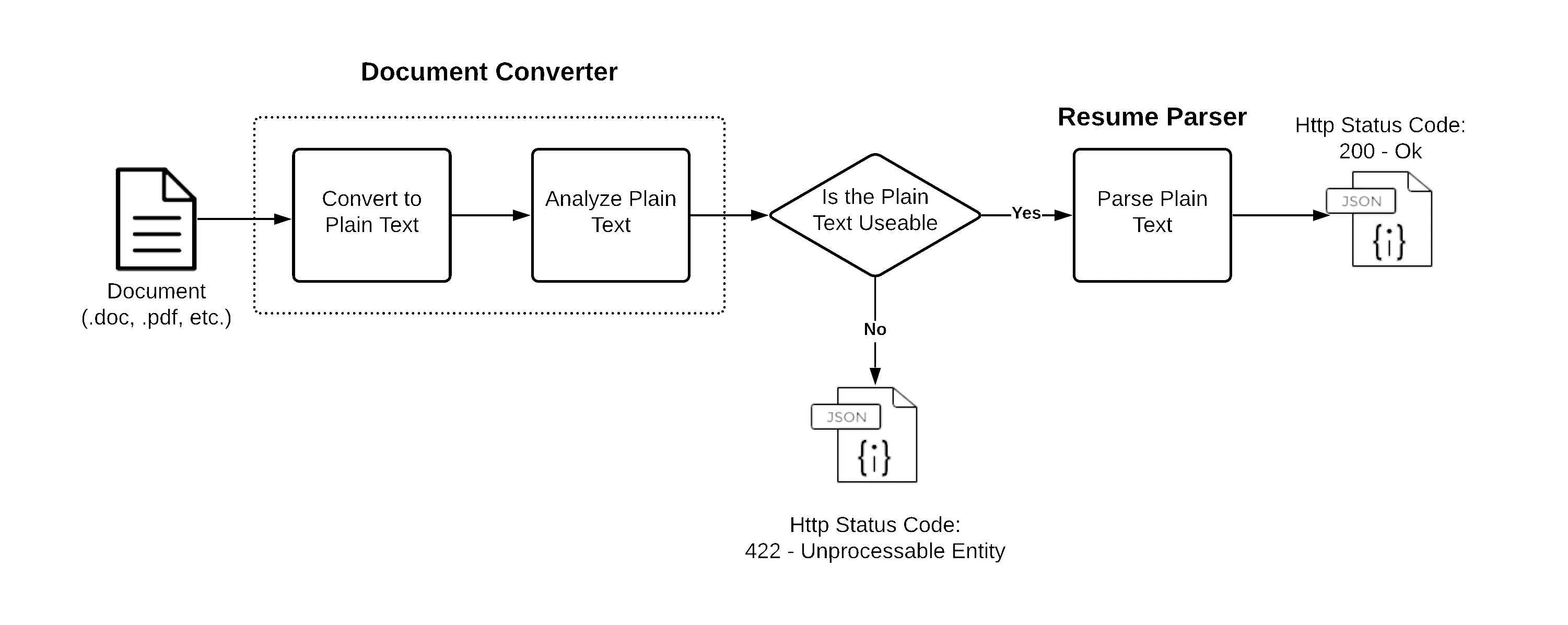
The vast majority of problems in parsing are not from processing the plain text, but from conversion to plain text. For example, there are many ways documents can be corrupted, or how they look like they are laid out isn't actually how the text is written. The point of explaining this is that when you find a mistake in the output, don't assume it's a parsing mistake. Look at the converted text and see if the converted text is as expected (reads logically). If the converted text is malformed, we cannot fix it.
Optical Character Recognition🔗︎
Optical Character Recognition (OCR) ensures that scanned or photographed documents are automatically detected and converted into text, so that the text can be parsed. Without OCR, such documents cannot be parsed. On average, approximately 5% of documents require OCR.
OCR does not impact the response time for non-image documents. However, for documents that do require OCR, the response time is higher due to the computational intensity involved with converting images to text. Because of this computational intensity, we also limit OCR to 10 pages and will stop processing the document after 120 seconds.
When OCR is enabled, a small additional transaction cost is incurred with each parsing transaction. Scans and full image documents are then auto-detected and OCR is applied when necessary. OCR can be configured in the Tx Console.
Documents That Can Cause Problems🔗︎
If you want to minimize conversion problems, don't use PDF documents. Many PDFs convert/parse fine; however, the reason for most of our "this document did not parse correctly" bug reports is that the document is a corrupt PDF file. PDF is a broken standard that often hides issues with the underlying text. If a PDF is corrupt, there is nothing Textkernel can do to make that document convert to text "as a human would read it".
Besides corrupt PDFs, we can predict - with very high accuracy - certain types of resumes that will not give satisfactory results.
Artists & Graphic Designers🔗︎
The goal of these resumes is to create the most visually unique document representing their skills as a designer. This prevents accurate text extraction because candidates will use images instead of text, have text run diagonally across the resume, use vertical text, etc. Parsing can only be as accurate as the text extracted from the source document.
Extremly Long CVs Typical in Academia & Medicine🔗︎
These documents are usually tens of pages and are flooded with patents, publications, and speaking events. They have very uncommon ways of writing work experience, and since they are often at a school or university it is easily confused with education.